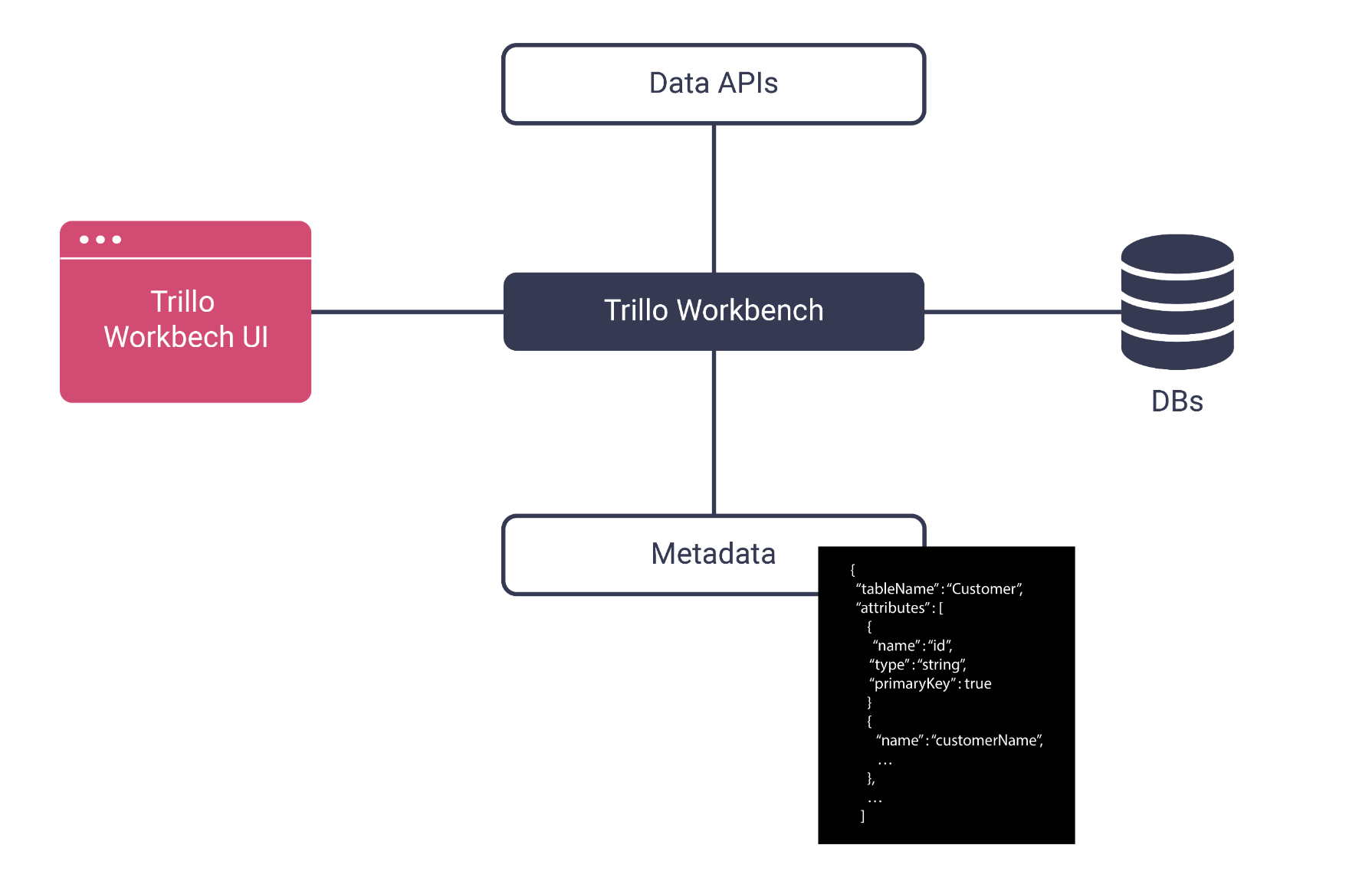
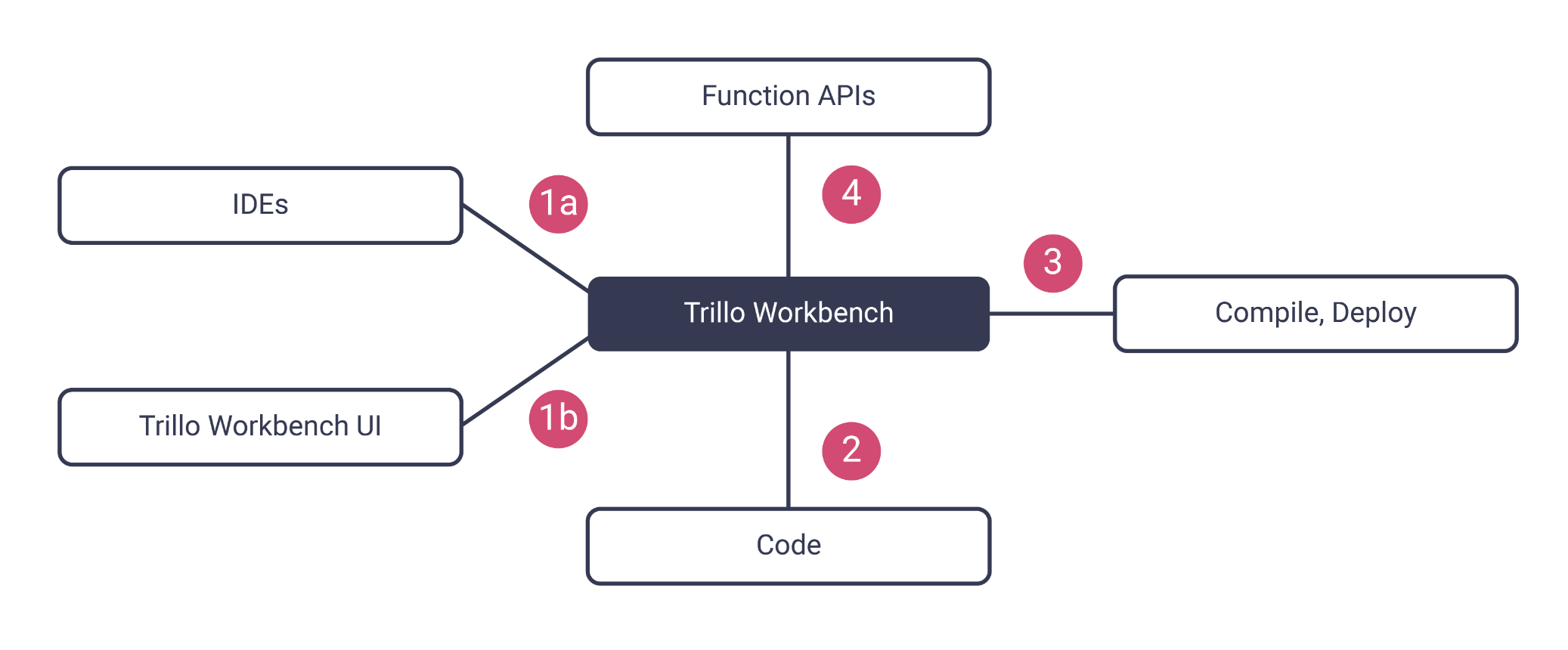
When building a typical application, engineers will use the Trillo Workbench UI, an editor, or an IDE to create the application data model, business logic, workflow, and domain metadata.
Application data model: An application uses multiple databases each with hundreds of tables. Writing programs to create and access database tables is a tedious and time-consuming task. Trillo Workbench simplifies this by using metadata to specify the data model.
Using Trillo Workbench, you will create your database metadata in JSON using either the Workbench UI or your own text editor.
Workbench will use this JSON metadata to transparently create the cloud databases, schemas, tables, column specifications, indexings, etc. It will also create APIs that your application will access to perform database operations.
At runtime, Workbench will manage the database connections, transaction integrity, role-based access control (RBAC), encryption, audit logs, and more.
Business Logic: In Trillo Workbench, you write business logic as modular serverless functions. These serverless functions are similar to Cloud Functions (GCP) or Lambda (AWS) but do not require cloud expertise. Instead, you use Workbench’s API abstraction. Trillo Workbench automatically deploys and publishes each function as an endpoint through its gateway.
It should be noted that serverless functions can also be executed asynchronously as a way of improving performance in some scenarios.
Examples of API functions that can be created with Workbench include:
Workflow: Trillo Workbench makes it a breeze to write simple or complex backend workflows. Workflows are written similarly to the serverless functions mentioned above.
Workflows run asynchronously and the lifecycle of the jobs is fully managed by Trillo Workbench.
Domain Metadata: The domain metadata is useful for writing configurable applications. Engineers specify domain metadata as JSON files using the Workbench UI or an editor. Functions can access this metadata at runtime using APIs. Likewise, Trillo Workbench lets you customize its existing services using metadata (for example Open ID Connect can be configured for Okta authentication using a JSON file).
The following diagram shows how to create custom APIs for database operations.
Using Existing Database
Trillo Workbench can connect to an existing database using the JDBC interface. It saves database schemas as
metadata. You can augment it to include other meta-info such as role-based access control, encryption,
validation, etc.
APIs Using Complex JDBC Queries
In an application it is often required to design an API to retrieve data using complex queries (with joins,
grouping, sorting, subqueries, etc.). To publish them as APIs, you would normally write a function. In
Trillo Workbench you write queries using curly braces for parameters. Workbench publishes each query as an
API.
Using Trillo Workbench, business logic is written using modular functions.
An application uses several metadata files for configuration specification such as external APIs, identity providers, data mapping, etc. Trillo Workbench lets you manage them as domain metadata in JSON or XML files. You can use them in code that depends on metadata.
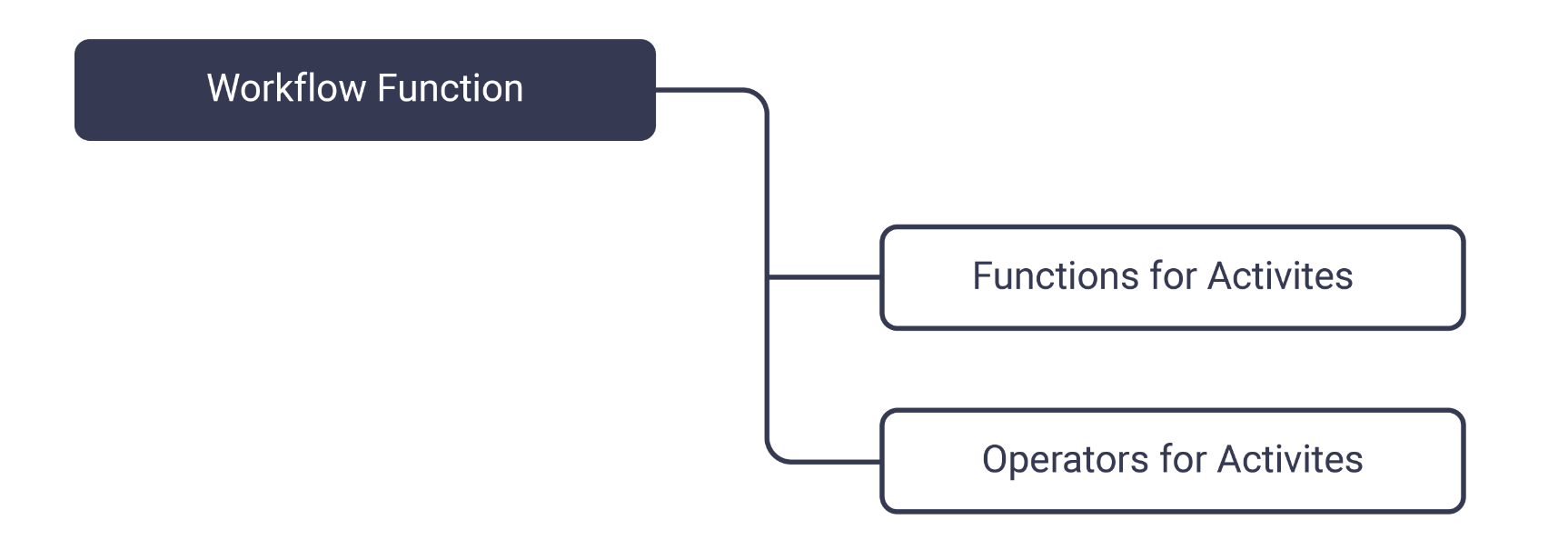
Trillo Workbench uses functions for the workflow definition. In addition, it provides operator classes for increasing concurrency. Typically, you use operators or other functions for activities (steps of a workflow). A higher-level function can sequence activities as workflows. A function keeps workflow abstraction as simple as any other program. Trillo Workbench manages the workflow lifecycle, maximizes concurrency, and deals with the audit logs. The workflow design is generic, it can be used in API calls to increase concurrency, for example fetching data from more than one external system.
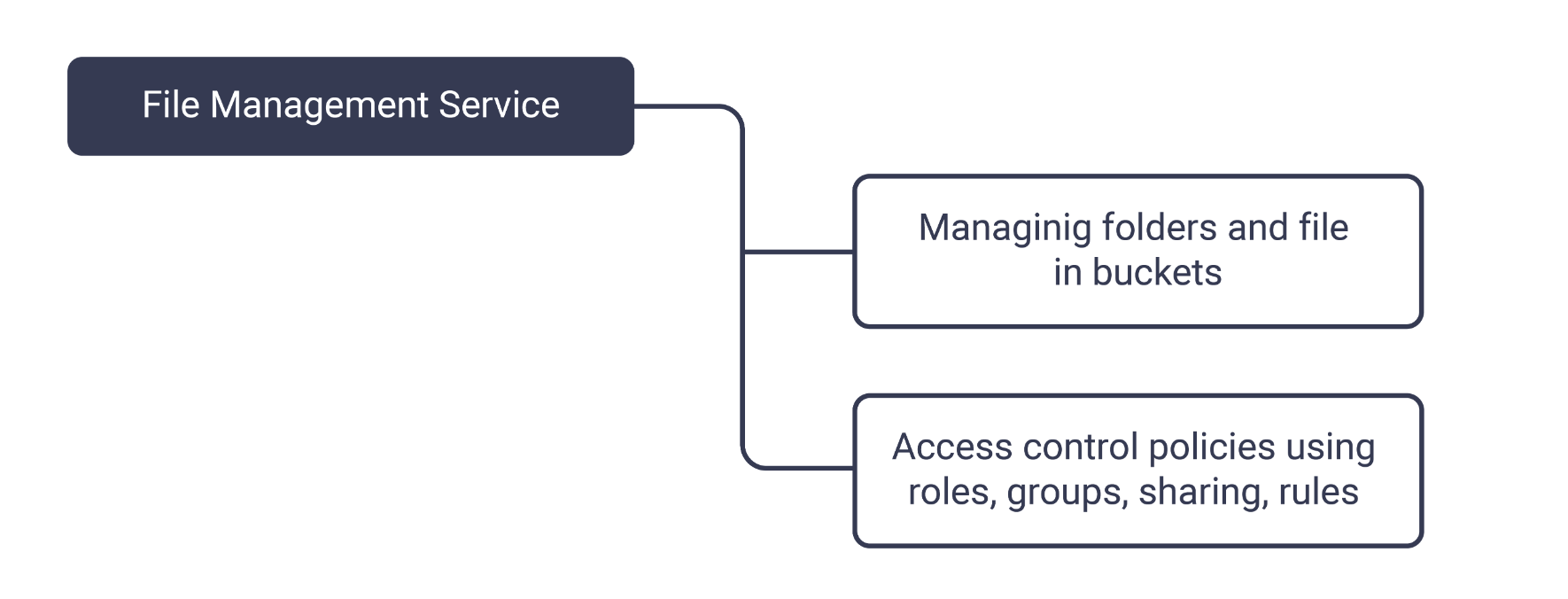
The File Management Service provides higher-level APIs to manage application files in buckets. The API is a
common denominator of several applications built using Trillo Workbench. Trillo Workbench also imposes
access control on access and update of files.
These APIs are used by Trillo File Manager (an application product that is provided with
Workbench).
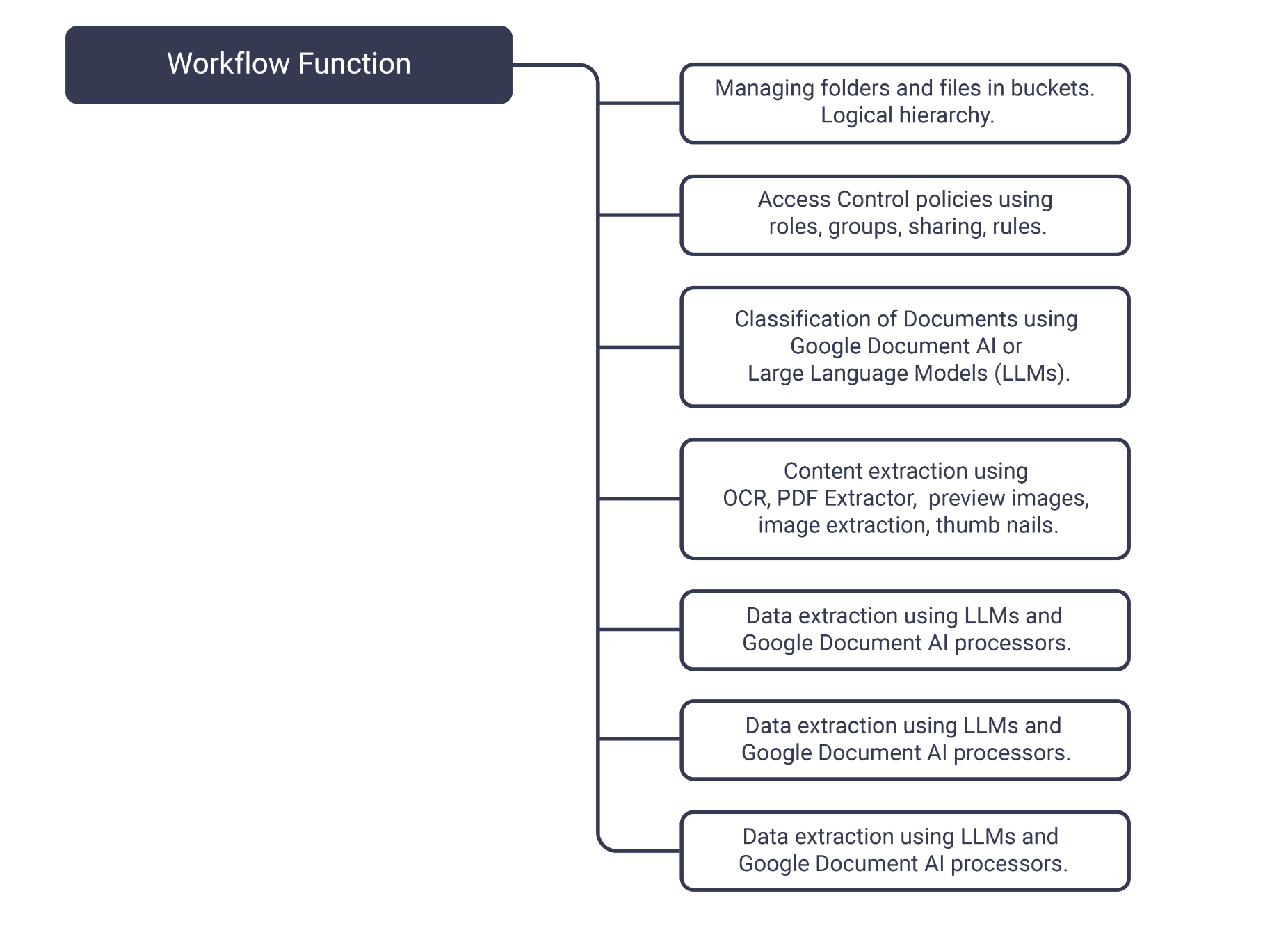
Trillo Doc Management Service provides intelligent document management using Document AI and Generative AI. Its features include the following components and APIs:
The executions of background tasks are recorded in the database.
Trillo Workbench logs important events in the database and cloud logs (GCP Stackdriver/ Operation Suite). It
includes information such as the operation name (e.g. create, file upload, delete, etc.), user, date-time,
short-description, severity, etc.
Using Audit Logs and Task History, you can troubleshoot 95% of issues. Cloud logs are used for the remaining
5%.
A function can invoke restful APIs using Trillo Workbench. The restful APIs use OAuth2 protocol for authorization. Trillo Workbench lets you enter credentials using the UI. (All credentials are encrypted and stored securely).
In addition to integrating with external systems, a new application can also use enterprise identity systems such as LDAP, Active Directory, or 3rd party services such as Google Cloud Identity, Okta, One Login, etc. Trillo Workbench provides integration with external authentication services using OIDC protocol. All you need to do is enter external system integration specifications – endpoints and credentials. (Trillo Workbench can also support integration with legacy authentication systems using SAML).
Settings are meta information used within an application. These are divided into the following categories.
User Management Application is a full application including user interface. It is required to store user records (actual or proxy in case of an external identity integration). Other optional uses are:
In our experience, Trillo Workbench covers approximately 90% of the core platform. You can focus on domain-specific parts.
Trillo Workbench implementation itself is a meta-architecture (meta meta-model), therefore adding 10% core is easy as well. You can do it yourself or ask Trillo.